A Guide to Getting the Most out of Leonardo.Ai
If you’ve made your way here, you’re probably looking forward to creating your own finetuned AI model
Leonardo.Ai makes it easy to get your own model going, and start generating anything you wish.
But even then, training can be a bit tricky for a first time.
So we made this guide to offer some useful tips though to make sure your model does well, and make stuff like this!

And this

And even these (which we’ll offer soon)
| Sprite 1 | Sprite 2 | Sprite 3 | Sprite 4 |
|---|---|---|---|
 |  |  |  |
Part 1: The Basics
First thing you’ll want to do is navigate over to the model training page, which can be found here.
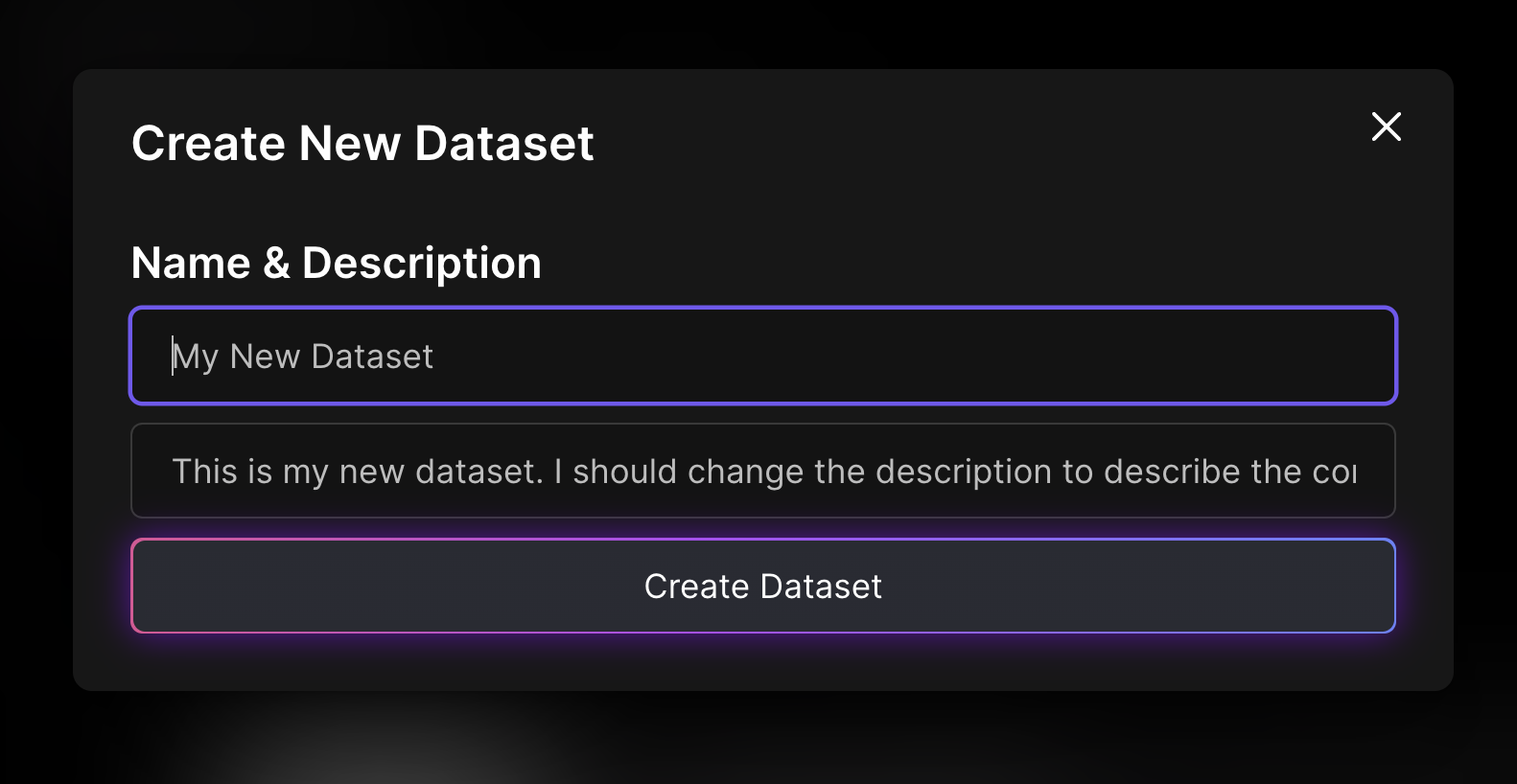
And then go ahead and click 👉Create New Dataset👈

From there, it will ask you to add a name and description for your dataset.
This will not affect the model quality, but its good to give it a name to help organize when you start building more datasets
A dataset is not the model, but just a collection of images you’ll feed to the machine to help it learn the style and content you want.
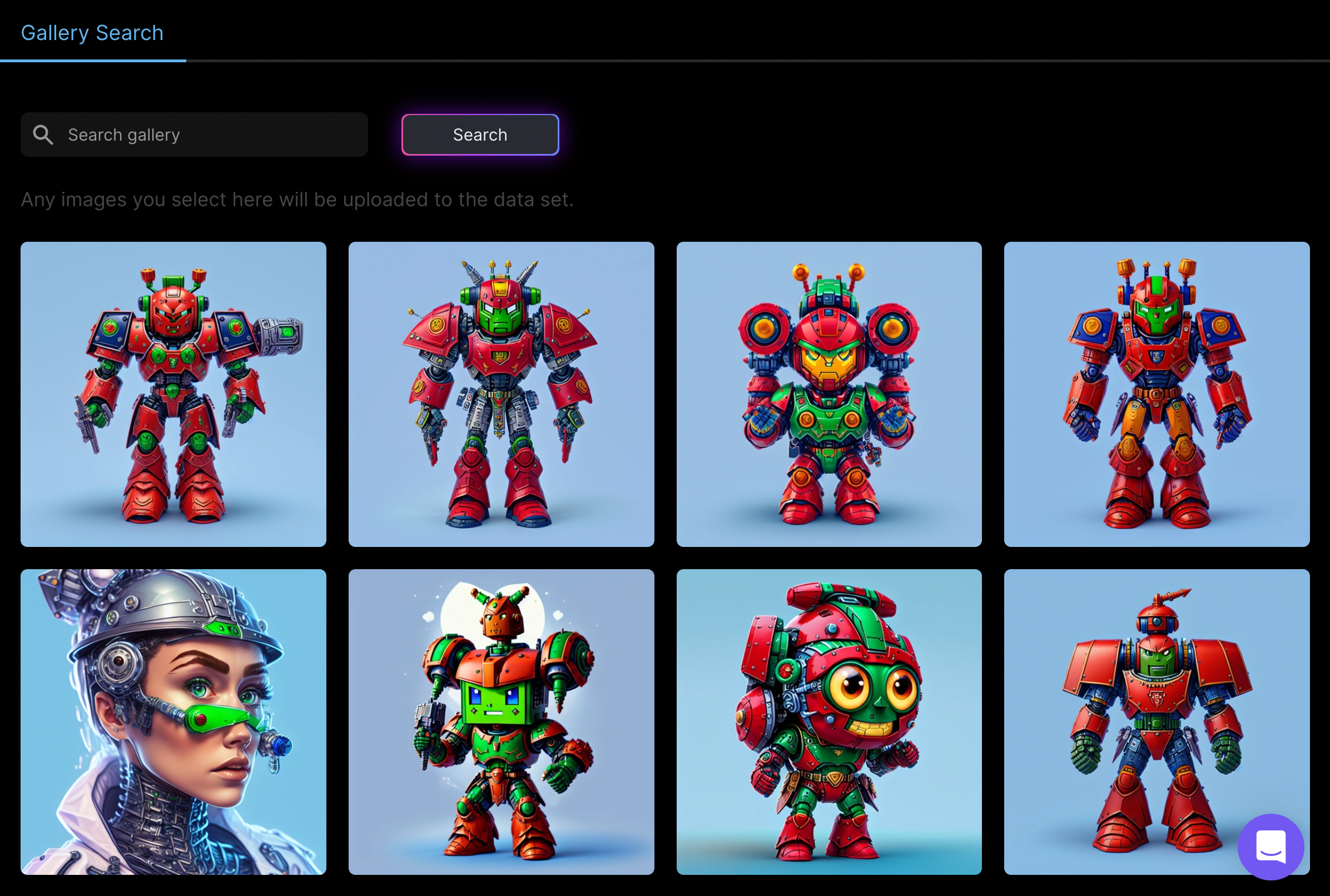
It’ll then take you to the “Edit Dataset” tab where you can then upload your images.

Need some inspiration? If you scroll down a bit, we have a gallery of images you can add to your dataset.
Simply clicking on an image will add it to your dataset
Here, I now have the first 5 images of my dataset
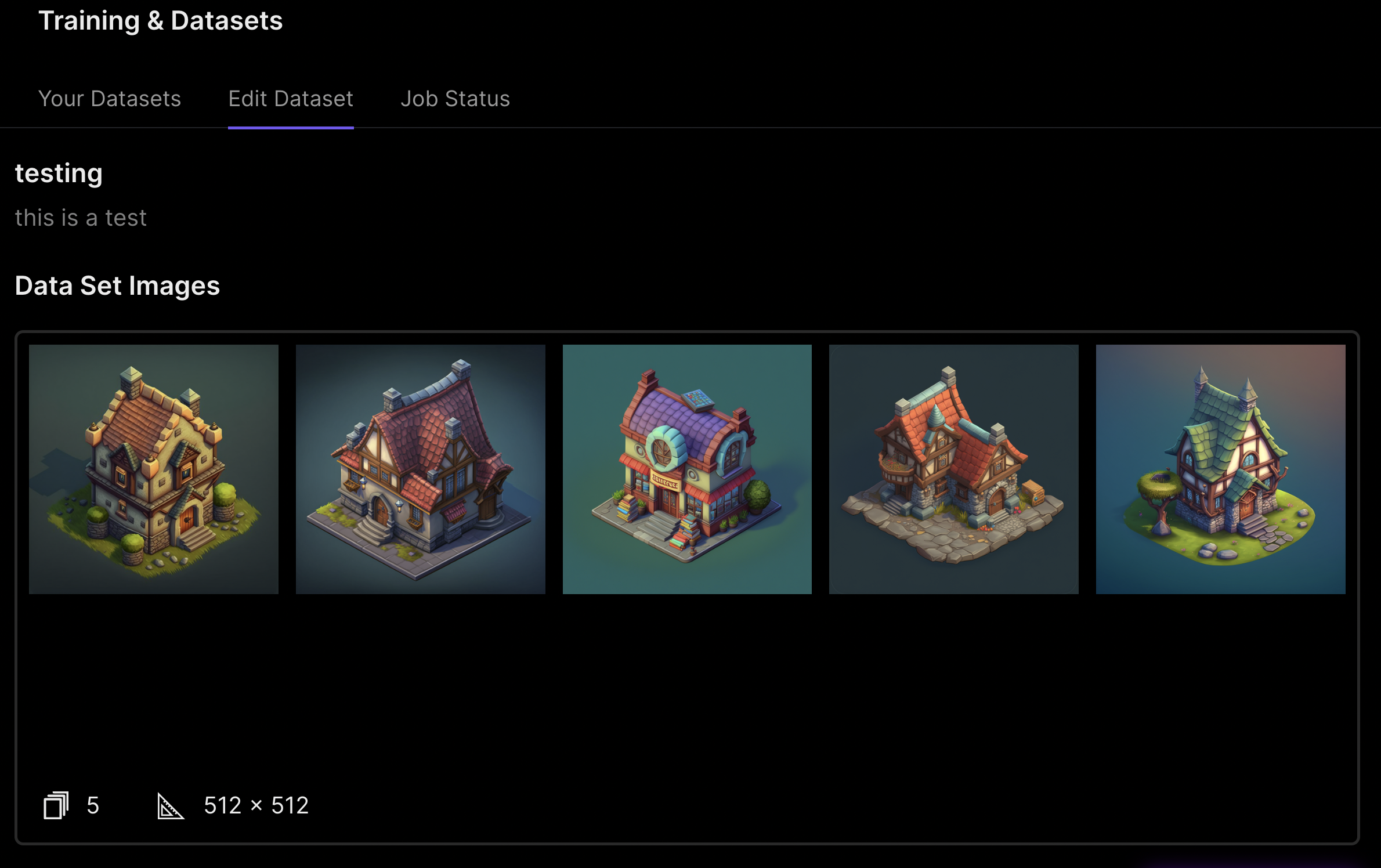
You can remove images from your dataset by clicking on any images you’d like to remove, and then clicking the “Remove Images” button
This can come in handy! A good dataset is often quality over quantity.
When adjusting a dataset after a training run to give it another try, it is sometimes useful to remove certain images that may not fit well with the rest of the dataset
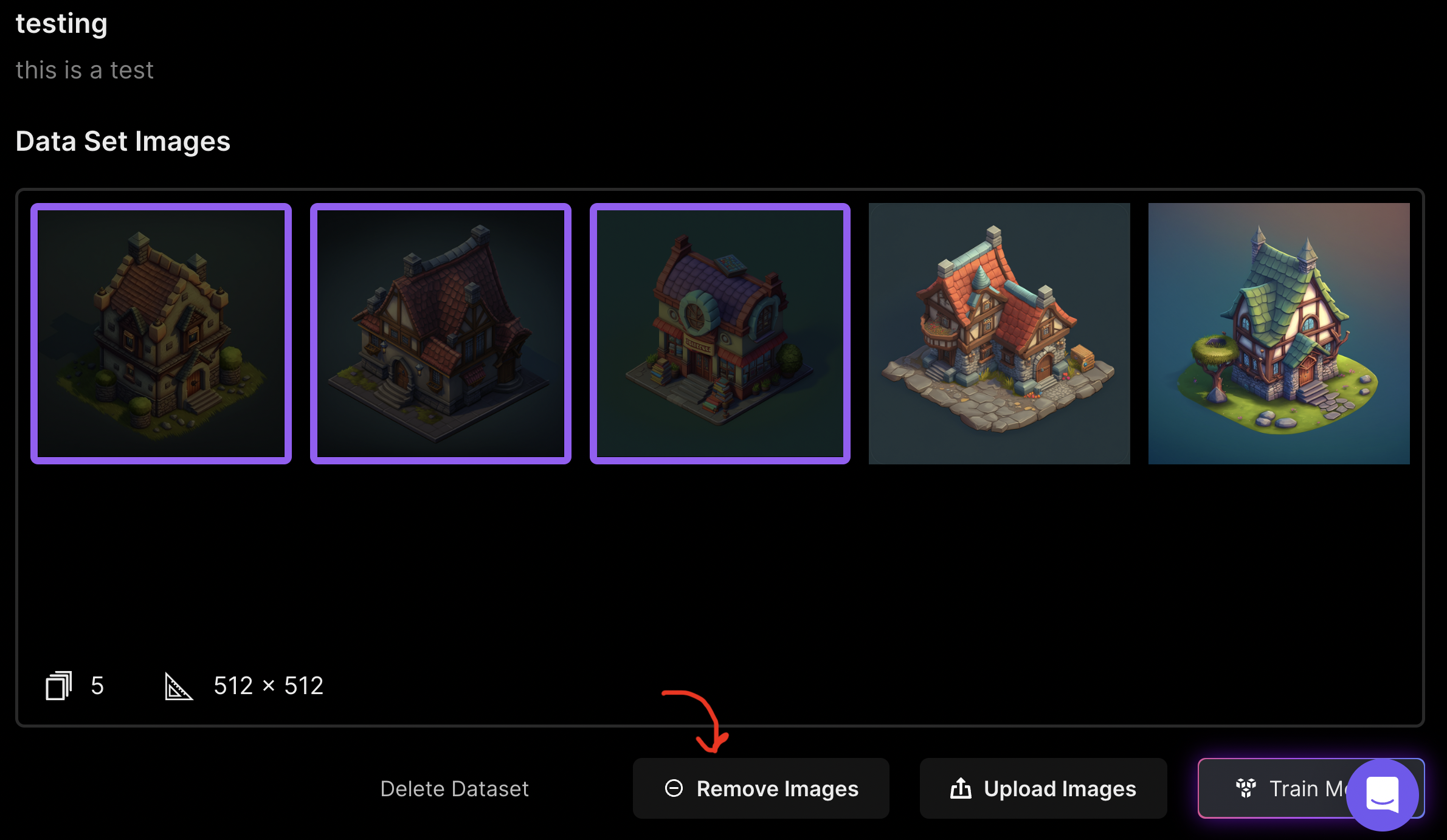
*You can also delete the entire dataset if you no longer need it.
Part 2: What makes a good training run
Now that we got all the basics of getting things set up, we can get to training our model
Number of Images
For this run, I’ll be using 14 images
A good sweet spot is around 8-15 images. But feel free to experiment with beyond that range!
Although I do not advise going below 5 images. And it isn’t necessary to go any higher than 30 really, and can potentially hurt quality
Suggested
ideal: 8-15 images
min: 5 images
max: 30 images
This number also depends on what you’re training on. In general, training an object does not require as many images training a style seems to require more images

Dataset Characteristics
Variation vs Consistency
Consistency
It is important that there is a common theme or pattern between your images for the model to learn from
While there’s tons of different things that work, the dataset I used is a good example because all of the images share a certain camera angle and graphic style
The elements that are consistent between images are what the model learns, and will generally show up in all of the outputs.
But on that same note, it is also a good idea to have a good amount of variation between the images. Otherwise the model can “overfit” and get stuck on certain things that maybe we don’t want in our outputs and not listen so well to our prompts
Variation Things that vary across your images will be more loosely learned, this is what allows your model to put your trained object (the consistent elements) in new kinds of styles and contexts
There’s no perfect answer to the optimal balance between Variation and Consistency and it’s something to experiment with!
But here is an example to better illustrate what I mean
For example, if I wanted to train a model on cute animal characters,
- The character position, style and image composition would be the consistent element I want it to learn
- But I would want to vary the animal characters generated and the clothes they’re wearing
- So ideally, each image would show various animals in different clothes in the same position with a similar image composition (i.e. full body, front facing, on a plain background)
For training a character model…
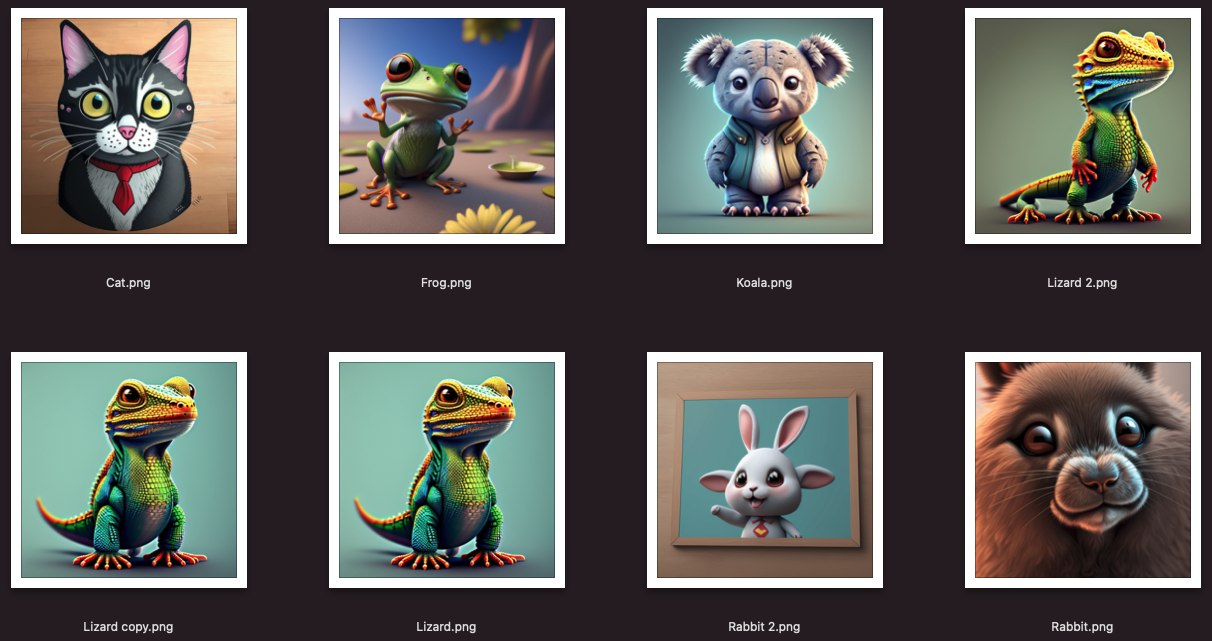
Here is an example of a BAD dataset ❌
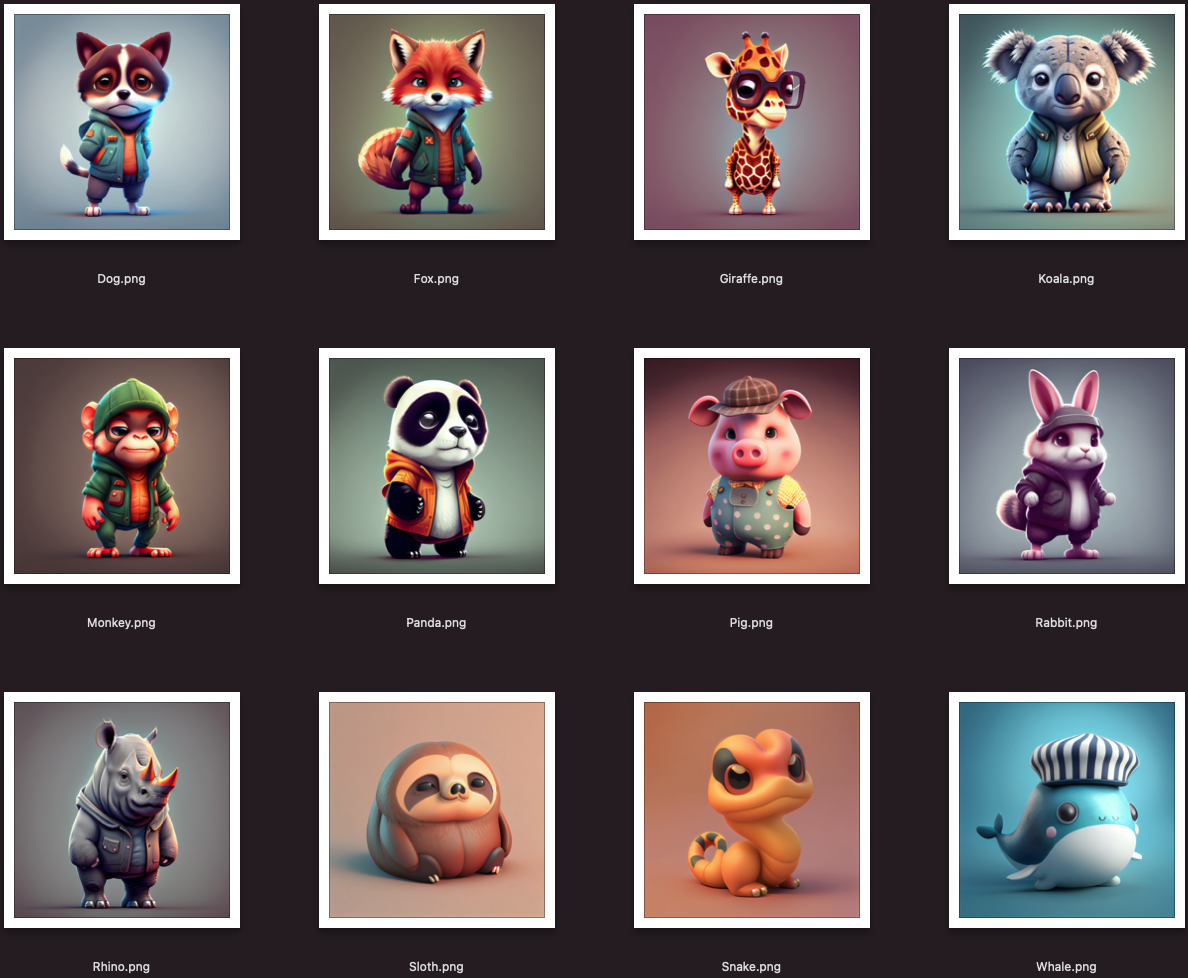
While this is a GOOD dataset ✅
Back to my original dataset, this would be our bad example, all we have is an orange house now So it will very likely only be able to output orange houses…

Quality The age old saying is “Garbage in, garbage out” so it is also a good idea to use high quality images.
Instance Prompt
Nothing too complicated here, just use 2-4 words to describe your images
so for my use case: “medieval building” or “a structure"
if you can’t think of any more than 1 word to describe your images, its all good! Just put “a” right before the word
Regardless of what you choose, you have to use the same phrase as the instance prompt when generating to make use of the training.
Although using portions of the instance prompt seems to be useful in its own way!
It is typically less strict to the dataset which can be useful when used correctly
Congratulations! You’ve made it to the end model training crash course! You’re now ready to go ahead and train your model.
If you have any feedback or questions, you can submit a ticket via our discord.
Join the Leonardo.Ai Discord Server! (opens in a new tab)
In the bottom right corner, you can also click this button to send a message to staff